





In recent years, deep learning has profoundly impacted computer vision and image processing, bringing about significant advancements and changes. Convolutional neural networks (CNNs) have been the driving force behind this transformation due to their ability to efficiently process large amounts of data, enabling the extraction of even the smallest image features. However, a new advancement has emerged in the field of deep learning: the Vision Transformer model (ViT), which is gaining popularity due to its efficient architecture and attention mechanism, and has shown promising results in various visual tasks such as image classification, object detection, and segmentation. Introduced in 2021 by Dosovitskiy et al., ViT breaks down images into a sequence of patches that are processed by a transformer encoder. This approach is more efficient as compared to traditional CNNs and eliminates the need for hand-engineered features such as transfer learning and large receptive fields. As ViT continues to develop, it has the potential to greatly improve accuracy and efficiency in the computer vision industry, making it a popular choice for processing and understanding visual data. This comprehensive guide on Vision Transformers provides a detailed understanding of ViT’s origin, construction, implementation, and applications.
- What is a Vision Transformer model?
- Importance of the Vision Transformer model
- The architecture of the Vision Transformer model
- How is a Vision Transformer model built and trained?
- Applications of Vision Transformers
What is a Vision Transformer (ViT)?
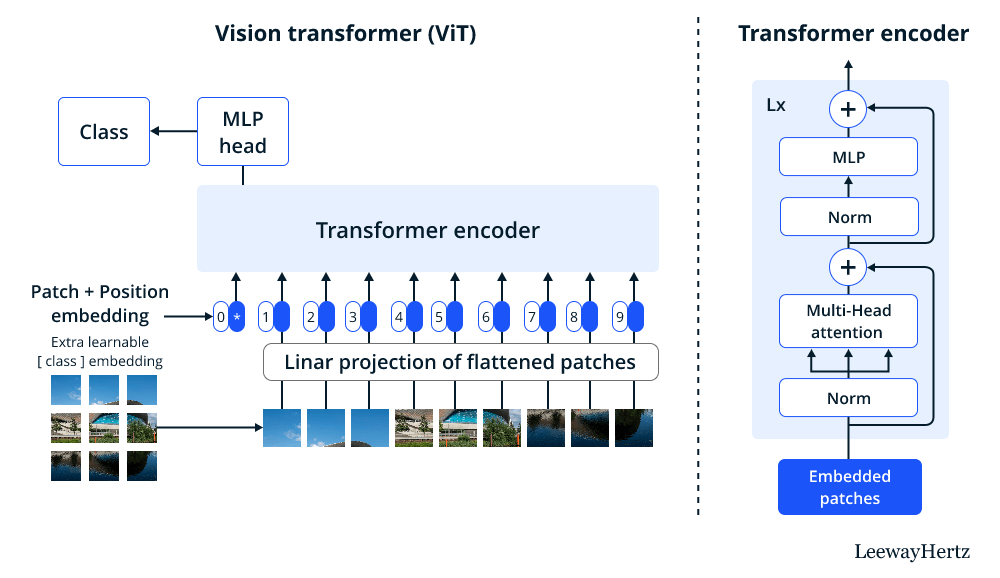
As proposed by Alexey Dosovitskiy in their paper, “An Image is Worth 16×16 Words: Transformers for Image Recognition” (2020), a Vision Transformer model is a type of neural network architecture designed for computer vision tasks. It is based on the Transformer architecture, originally introduced for natural language processing tasks, but adapted to work with image data.
The Vision Transformer model represents an image as a sequence of non-overlapping fixed-size patches, which are then linearly embedded into 1D vectors. These vectors are then treated as input tokens for the Transformer architecture. The key idea is to apply the self-attention mechanism, which allows the model to weigh the importance of different tokens in the sequence when processing the input data. The self-attention mechanism allows the model to capture global contextual information, enabling it to learn long-range dependencies and relationships between image patches.
The Vision Transformer model consists of an encoder, which contains multiple layers of self-attention and feed-forward neural networks, and a decoder, which produces the final output, such as image classification or object detection predictions. During training, the model is optimized using a suitable loss function, such as cross-entropy, to minimize the difference between predicted and ground-truth labels.
One of the advantages of the Vision Transformer model is its scalability. It can be trained on large image datasets, and its performance can be further improved by increasing the size of the model and the number of self-attention heads. Additionally, Vision Transformers have shown to be competitive with or even outperform traditional Convolutional Neural Networks (CNNs) on several computer vision benchmarks, with the added benefit of being more interpretable due to their self-attention mechanisms.
While Vision Transformer models may require more computational resources than CNNs due to their self-attention mechanisms and sequential processing of patches, they have garnered significant attention in the computer vision community as a promising approach for image recognition tasks. They have been used in various applications such as image classification, object detection, semantic segmentation, and image generation. Overall, the Vision Transformer model is a novel and powerful architecture that combines the strengths of Transformers and computer vision, offering a new direction for image recognition research.
Importance of the Vision Transformer model
The Vision Transformer model, a powerful deep learning architecture, has radically transformed the computer vision industry. ViT relies on self-attention processes to extract global information from a picture, making it a very effective tool for image classification tasks. In contrast to conventional Convolutional Neural Networks (CNNs), image recognition applications widely employ ViT tools for image identification tasks.
The main benefit of the ViT model is its ability to automate the manual process used for featured image extraction. In the past, the manual process of extracting features from the image was time-consuming and expensive. The ViT model’s automated feature extraction procedure enables end-to-end training on huge datasets. Because of this, it is very scalable and flexible for a variety of applications.
The capacity of the ViT model for gathering global contextual information in photos is another major benefit. Conventional CNNs are only capable of collecting local information, which makes it difficult to identify intricate patterns to grasp the larger environment. ViT’s self-attention technique enables it to identify patterns and capture long-range relationships that conventional CNNs could overlook. As a result, it excels at jobs like object identification, where the capacity to identify things in challenging settings is crucial.
Furthermore, ViT can be pre-trained on large datasets, making it highly effective for transfer learning with limited data. Transfer learning allows the model to leverage the knowledge gained from pre-training on large datasets and apply it to new tasks with limited labeled data. This is particularly useful in applications such as medical image analysis, where labeled data can be scarce and expensive to acquire.
The ViT model has a wide range of applications in industries like medicine, agriculture, and security because of its capacity to automate the feature engineering process, gather global contextual information, and use pre-training on massive datasets.
Contact LeewayHertz for consultancy and development
The architecture of a Vision Transformer (ViT) model
The Vision Transformer model has a powerful deep learning architecture for all the computer vision tasks and it is mainly based on the foundation of the original transformer design, which was first presented for problems related to natural language processing. The Vision Transformer model mainly comprises two important components: a classifier and a feature extractor. The job of the feature extractor is to extract significant features from the input picture, and the classifier’s job is to divide the input image into several classes.
The feature extractor consists of a stack of transformer encoder layers. Each transformer encoder layer constitutes a multi-head self-attention mechanism with a position-wise feed-forward network.
With the help of the self-attention mechanism, the model may focus on various elements of the input image and discover overall correlations between them. With this, each layer of the sequence receives a non-linear transformation from the position-wise feed-forward network in the input.
To consider each patch as a token in the input sequence, the input picture is first separated into fixed-size patches. And then, the model is able to learn the spatial connections between the patches, after which the positional encoding of each token is added to the associated patch embedding. At last, the patch embeddings and positional encodings are fed into the transformer encoder layers to extract meaningful features from the input image.
The output of the feature extractor is a sequence of feature vectors, one for each patch in the input image. To forecast the class label of the input picture, the feature vectors are then fed through a linear classifier. And here, the single fully connected layer of the linear classifier is followed by a softmax activation function.
The ViT architecture provides certain benefits over the conventional convolutional neural network (CNN) designs:
- First, it can handle inputs of any size without needing to alter the model design further.
- Second, it can discover general correlations between various elements of the input picture, which is particularly advantageous for tasks like object segmentation and detection.
- Lastly, it is more computationally efficient due to having fewer parameters than conventional CNN structures.
How is a ViT model built and trained?
The primary concept of the ViT model is to treat an image as a series of patches, which are discrete, square-shaped portions of the image. After being flattened, these patches are converted into a series of 1D vectors that may be fed into a transformer model as input. This series of patch vectors is used to train the Transformer model to categorize the picture.
The procedures for creating and training a ViT model are as follows:
-
- Dataset preparation: This involves collecting a large number of images and labeling them with corresponding class labels. The dataset should be diverse, containing images from various angles, backgrounds, and lighting conditions. The dataset should also be split into training, validation, and test sets to ensure that the model can generate new data. Dataset preparation is critical to the success of a ViT model, as it determines the quality of data that the model will be trained on. A well-prepared dataset helps ensure the model can recognize and classify images accurately.
- Preprocessing: Preprocessing is a crucial step in building a Vision Transformer (ViT) model. Preprocessing aims to prepare the input image for token embedding and ensure that the input data is in a suitable format for the model. The preprocessing step involves several steps:
- Resizing the images: The input images are resized to a consistent size. This ensures that all images have the same dimensions, making processing easier.
- Normalizing pixel values: The pixel values of the input images are normalized to make the training process more stable. This is done by subtracting the mean pixel value of the dataset and dividing it by the standard deviation.
- Data augmentation: Data augmentation is a technique used to increase the size of the dataset and improve the model’s ability to generalize to new data. Common data augmentation techniques include random rotation, flipping, cropping, and changing the brightness and contrast of the images.
- Data splitting: The dataset is split into training, validation, and test sets. The training set is used to train the model, the validation set is used to monitor the model’s performance during training, and the test set is used to evaluate the final performance of the model.By properly preprocessing the input images, developers can improve the quality and accuracy of the ViT model. This step ensures the model is trained on high-quality data well-suited for the image recognition task.
- Importing libraries: This step involves importing libraries and modules into the programming environment to use their functionalities. The most commonly used libraries and modules for building ViT models are PyTorch, NumPy, and Matplotlib.
- PyTorch: It is a popular open-source machine-learning library for building deep-learning models. It provides a simple, flexible programming interface for creating and training deep learning models, including ViT.
- NumPy: It is also a powerful library for numerical computing in Python. It is used for handling large arrays and matrices of numerical data.
- Matplotlib: Matplotlib is mainly used for creating visualizations in Python. It can be used to plot the performance metrics of the ViT model during training and evaluation.
- Building the model architecture: Building model architecture is a crucial step in creating a Vision Transformer (ViT) model. The model’s architecture defines its structure and determines how it will process the input data. The ViT architecture consists of a series of transformer blocks, each containing a self-attention mechanism and a feedforward network. The self-attention mechanism allows the model to focus on different parts of the input image, while the feedforward network applies non-linear transformations to the extracted features. The number of transformer blocks and the dimensions of the hidden layers can be adjusted based on the input image’s complexity and the dataset’s size. By building an effective model architecture, developers can ensure that the ViT model can accurately recognize and classify images, making it a powerful tool for a wide range of image recognition tasks.
- Training the model: Model training is critical in building a Vision Transformer (ViT) model. The training process involves feeding the model with input images and the corresponding labels and adjusting its parameters to minimize the loss function. During training, the model learns to extract meaningful features from the input images and maps them to the corresponding labels. The training process typically involves iterating through the entire dataset multiple times (epochs), with the model updating its parameters after each iteration. Regularization techniques such as dropout or weight decay can be applied to avoid overfitting when the model performs well on the training set but poorly on new, unseen data.To evaluate the performance of the ViT model during training, metrics such as accuracy, precision, recall, and F1 score can be used. The training process can be stopped when the model achieves satisfactory performance on the validation set, which helps prevent overfitting. Once the ViT model is trained, it can be used for inference on new, unseen images to make accurate predictions. Proper training is essential to ensure the ViT model performs well and can recognize and classify a wide range of images.
- Hyperparameter fine-tuning: It is one of the crucial steps in optimizing the performance of a Vision Transformer (ViT) model. It involves tweaking the model’s hyperparameters to obtain the best possible performance on a given task.
The first step in hyperparameter fine-tuning is selecting a set of hyperparameters to modify, such as the learning rate, batch size, number of layers, or attention heads. A hyperparameter search method, such as grid search, random search, or Bayesian optimization, is employed to explore the hyperparameter space and find the combination that results in the highest performance.
During hyperparameter fine-tuning, the ViT model is trained on a portion of the dataset and validated on a separate portion. The performance metrics obtained from the validation set are used to guide the search for optimal hyperparameters. This process is repeated until the best set of hyperparameters is identified, and the ViT model is trained on the entire dataset using these optimized hyperparameters.
It’s important to note that hyperparameter fine-tuning can be computationally expensive and time-consuming. Therefore, techniques such as early stopping, model selection based on validation metrics, and transfer learning can be used to optimize the process and reduce the computational cost.
Implementation of a Vision Transformer (ViT) model for image classification
Here we will be demonstrating the image classification process of a Vision Transformer with the help of hugging face
Step 1 – This step involves the installation of the transformer’s library
pip install git+https://github.com/huggingface/transformers.git
Step 2 – Import required libs/ modules/ classes
First, we are importing the ViT feature extractor and ViT image classification from the transformer, and second, we are importing the PIL image and, lastly, the request to get the https.
from transformers import ViTFeatureExtractor, ViTForImageClassification from PIL import Image import requests
Step 3 – Download the image from the given URL: for the extraction and classification
# url = 'https://images.unsplash.com/photo-1503023345310-bd7c1de61c7d?ixlib=rb-4.0.3&ixid=MnwxMjA3fDB8MHxzZWFyY2h8Mnx8aHVtYW58ZW58MHx8MHx8&w=1000&q=80'
Step 4 – Display the downloaded image
#from IPython.display import Image

Step 5- Loading the classes from the pre-trained model google/vit-base-patch16-224
feature_extractor = ViTFeatureExtractor.from_pretrained('google/vit-base-patch16-224')
model = ViTForImageClassification.from_pretrained('google/vit-base-patch16-224')
Step 6 – Extracting features
inputs = feature_extractor(images=image, return_tensors="pt")
Step 7- Model Inference
outputs = model(**inputs) logits = outputs.logits <ipython-input-9-28bb361019f7> in <cell line: 1>()----> 1logits=outputs.logits
Step 8- Model predicts one of the 1000 imagenet classes
predicted_class_idx = logits.argmax(-1).item()
print("Predicted class:", model.config.id2label[predicted_class_idx])
Predicted class: palace
So the output generation of the image classification is “palace.”
Applications of Vision Transformers
Image classification

For image classification, the ViT model divides the input picture into a series of non-overlapping patches, which are then flattened and fed into the Transformer network. The Transformer’s self-attention mechanism enables the model to learn contextual relationships between patches, which enables it to recognize intricate visual elements and patterns. The ViT model consistently outperforms classic CNN models on various datasets in several image classification benchmarks. It is computationally more efficient than CNNs and can handle bigger pictures without down-sampling since it does not rely on spatial convolutions.
Image captioning

Vision Transformer (ViT) has shown great potential in image captioning, which means generating a textual description of an image. ViT employs the transformer architecture to carry out the same task as conventional image captioning algorithms, which combine convolutional neural networks (CNNs) and recurrent neural networks (RNNs) to extract visual information and produce captions. The model initially runs the picture through a pre-trained ViT encoder to extract visual characteristics in order to use ViT for image captioning. The language model decoder uses the produced feature vectors to provide the textual description of the image. ViT can learn to represent pictures in a way that is more meaningful semantically and contextually aware, which might result in more precise and useful image analysis.
One of the key advantages of using ViT for image captioning is its ability to capture long-range dependencies between visual features and textual context. The self-attention mechanism in the transformer architecture allows the model to attend to different parts of the image and the generated captions, enabling it to learn more complex relationships between visual and textual information. This can result in more coherent and relevant captions that better capture the nuances and context of the image.
Contact LeewayHertz for consultancy and development
Image segmentation
Image segmentation is the process of splitting an image into several parts or segments depending on its visual properties. Vision Transformers have demonstrated great potential for this task. Generally, ViT’s model is altered here so that an encoder-decoder framework is incorporated to use it for picture segmentation. In this method, the input picture is first run through the ViT encoder, which uses the self-attention process to extract features from the image. The decoder next receives the encoder’s output and creates a segmentation map by upsampling and merging data from various encoder levels.
Another approach to using ViT for image segmentation combines it with other methods, such as convolutional neural networks (CNNs) or region proposal networks (RPNs). In this approach, ViT is used to extract global features from the image, while CNN or RPN is used to extract local features and generate proposals for object boundaries. The two sets of features can then be combined to generate a final segmentation map.
As compared to traditional CNNs, using ViT offers the benefit of capturing long-range dependencies between image pixels. ViT can also handle larger input images without the need for down-sampling, which can help preserve fine-grained details in the segmentation map.
Anomaly detection
Anomaly detection is the process of identifying data points that deviate from the expected normal behavior in a dataset. In the context of images, this could be identifying an object that is not supposed to be in the image or detecting a defect in the visuals.
The use of ViTs in anomaly detection entails training the model on a sizable dataset of photos showing anticipated or normal behavior and then using it to find images that vary from the normal. To categorize new pictures as normal or anomalous depending on their reconstruction error, one method is to train a ViT model using a dataset of normal images. Using the encoded characteristics produced by the ViT model, a reconstruction network that attempts to recreate the original picture is trained in this method. The difference between the original and reconstructed images is a measure for spotting anomalies.
Another approach is to use the ViT model as a feature extractor and feed the extracted features into a separate anomaly detection model, such as an autoencoder or a one-class SVM (support vector machines). The anomaly detection model is trained on the extracted features to identify deviations from the expected behavior.
ViT-based anomaly detection has demonstrated encouraging results in many applications, including surveillance, manufacturing quality control, and medical imaging. ViT models’ self-attention capabilities may capture fine-grained features in the pictures that conventional convolutional neural networks could miss.
Action recognition
When employing ViTs for action recognition, the model is first trained on a significant part of the video data before being applied to classify fresh movies into distinct action categories. One method is to feed the extracted features into a different classification model, such as linear SVM or a neural network, using a pre-trained ViT model as a feature extractor. To recognize the various activities in the movies, the classification model is trained using the retrieved characteristics.
Another way to use ViTs for action recognition involves modifying the self-attention mechanism to look at the temporal information in videos. In order to extend the self-attention process to the temporal domain, several attention heads are used to record the temporal correlations between the video frames. By analyzing the temporal correlations between the frames, ViTs can capture the dynamic progression of activities through time.
ViT-based action recognition has shown promising results in various applications, including sports analysis, security, and robotics. By leveraging the self-attention mechanisms of ViT models, it is possible to capture fine-grained details in the videos that traditional convolutional neural networks may not capture.
The application of ViT models in action recognition is an exciting area of research that has the potential to improve the accuracy and efficiency of action recognition systems significantly. As the field continues to develop, we can expect to see more innovative approaches that leverage the unique capabilities of ViT models to capture temporal dynamics in video data and improve the performance of action recognition systems.
Autonomous driving
Autonomous driving is an emerging field of research that aims to develop vehicles that can navigate and operate without human intervention. It requires sophisticated computer vision systems to assess the surrounding conditions and make real-time decisions. Deep neural networks such as Vision Transformers show promise in several computer vision applications, including object segmentation and detection. ViTs can, therefore, be used in autonomous driving for enhanced environmental awareness and vehicle safety.
Detecting and categorizing environmental factors, such as people, other cars, and obstructions, is a major challenge in autonomous driving. By learning from huge datasets of labeled photos and utilizing self-attention processes to take in fine-grained features in the environment, ViTs may be utilized to improve object recognition.
Another application of ViTs in autonomous driving, scene segmentation, involves dividing the image into different regions and assigning each region a semantic label, such as road, sidewalk, or building. This information can be used to improve the vehicle’s perception of the environment and make more informed decisions. ViTs can be trained on large datasets of labeled images to learn the various features and characteristics of different objects in the environment, making it easier to segment the image accurately.
ViTs can also be used for real-time decision-making in autonomous driving. By analyzing the environment and predicting the future behavior of objects, ViTs can help the vehicle make more informed decisions, such as when to accelerate, brake, or change lanes. This can improve the safety and efficiency of the vehicle, making it more suitable for real-world applications.
Endnote
To sum up, the Vision Transformer is an innovative deep-learning architecture that has completely changed the area of computer vision. Its ability to process images by dividing them into patches and attending to them using self-attention mechanisms has proven extremely effective in various applications, from image classification to object detection.
Implementing a ViT model requires careful attention to detail, as the architecture is more complex than traditional convolutional neural networks. However, with the right tools and techniques, a ViT model can be trained to achieve state-of-the-art performance on benchmark datasets. The ViT’s capacity to handle long-range dependencies in pictures, which typical convolutional neural networks find challenging, is one of its main features. This makes it the perfect framework for jobs like natural language processing and picture captioning that demand a high level of context awareness.
Overall, ViT is a major advancement in the field of computer vision and has already shown promise in a variety of use cases. The ViT is expected to become a crucial tool for deep learning practitioners as academics continue to improve its architecture and explore newer applications.
Looking to enhance your computer vision applications using Vision Transformer models? Get in touch with our team of AI experts for all your AI development and consultancy needs.
Author’s Bio


Akash's ability to build enterprise-grade technology solutions has attracted over 30 Fortune 500 companies, including Siemens, 3M, P&G and Hershey’s.
Akash is an early adopter of new technology, a passionate technology enthusiast, and an investor in AI and IoT startups.
Start a conversation by filling the form
All information will be kept confidential.
Insights

The future of workflow automation: Leveraging artificial intelligence for enhanced efficiency
AI workflow automation is the integration of Artificial Intelligence (AI) technologies with workflow automation to streamline business processes, improve efficiency, and drive innovation.

Generative AI in customer service: Innovating for the next generation of customer care
Generative AI transforms customer service by automating routine tasks, providing personalized assistance, ensuring 24/7 availability, and enhancing customer engagement.

AI for ITSM: Enhancing workflows, service delivery and operational efficiency
Leveraging AI in IT Service Management (ITSM) has become a game-changer for organizations seeking to streamline operations, boost productivity, and enhance customer satisfaction.



