





Over the past few years, artificial intelligence (AI) has been advancing significantly. We’ve seen remarkable advancements in areas like image recognition, speech-to-text conversion, and language translation. However, a key limitation of many current AI models is that they operate within a single data modality. An image recognition model, for instance, excels at processing visual information but struggles to understand the accompanying text description. This siloed approach restricts AI’s ability to grasp the complexities of the real world, where information is presented through a diverse collection of sights, sounds, and text.
This is where Large Multimodal Models (LMMs) come in. LMMs represent a transformative step forward in AI development. They break down the barriers between different data modalities, enabling them to process and understand information from various sources simultaneously. Just like humans use a combination of sight, sound, and touch to comprehend the world around them, LMMs can analyze text, images, audio, and other data types to gain a more holistic understanding.
This newfound ability to bridge modalities opens up exciting possibilities for AI applications. LMMs have the potential to transform numerous sectors, from healthcare and education to customer service and entertainment. Let’s delve deeper into the exciting world of Large Multimodal Models in this article and explore their capabilities in greater detail.
- Understanding Large Multimodal Models (LMMs)
- Differentiating LMMs from Large Language Models (LLMs)
- Tasks performed by Large Multimodal Models
- Data modalities of Large Multimodal Models
- How do Large Multimodal Models work?
- Use cases of LMMs across various industries
- LMM-powered agents
- Notable Large Multimodal Models
- Benefits of LMMs for businesses
Understanding Large Multimodal Models (LMMs)

Large multimodal models (LMMs) represent a significant advancement in artificial intelligence, enabling AI systems to process and comprehend multiple types of data modalities such as text, images, audio, and video. Unlike traditional AI models that are restricted to operating within a single modality, LMMs can integrate and interpret information from diverse sources simultaneously, mimicking the way humans interact with the world around them.
To grasp the significance of LMMs, it’s essential to understand the concept of modalities in AI. A modality refers to a specific kind of data, like text, images, or audio. In the past, machine learning models were primarily designed to work with one specific data type, such as text for language tasks or images for visual recognition. However, LMMs break free from these constraints by integrating multiple modalities into a single framework. The development of LMMs has expanded the capabilities of AI systems, allowing them to understand and generate outputs in various forms.
Incorporating multiple modalities into large language models (LLMs) transforms them into large multimodal models (LMMs). Over the past year, major research labs have introduced new LMMs such as DeepMind’s Flamingo, Salesforce’s BLIP, Microsoft’s KOSMOS-1, Google’s PaLM-E, and Tencent’s Macaw-LLM. Notable chatbots like ChatGPT and Gemini fall under the category of LMMs. However, not all multimodal systems qualify as Large Multimodal Models (LMMs). For instance, text-to-image models like Midjourney, Stable Diffusion, and DALL-E are multimodal but do not include a language model component.
Multimodal systems can refer to one or more of the following:
- Systems where input and output are of different modalities (e.g., text-to-image, image-to-text)
- Systems capable of processing inputs from multiple modalities (e.g., text and images)
- Systems capable of generating outputs in multiple modalities (e.g., text and images)
Integrating multiple modalities into a single model enables LMMs to tackle a wide range of tasks that were previously challenging for traditional AI systems. LMMs can understand spoken instructions, analyze images and videos, and generate responses in different formats, making them more versatile and adaptable to different use cases.
To achieve this level of versatility, LMMs require extensive training on diverse datasets that cover various modalities. This training process involves exposing the model to large amounts of data from different sources to learn patterns and relationships across multiple modalities. As a result, LMMs can handle complex and nuanced tasks that require understanding and processing information from different perspectives. This capability opens up many possibilities for AI applications, from more interactive chatbots to advanced image and video analysis systems.
Despite their potential, LMMs also face certain challenges and limitations. Training LMMs requires significant computational resources and expertise, making them inaccessible to smaller research groups or organizations with limited resources. Additionally, integrating multiple modalities into a single model can introduce complexities and potential performance issues, requiring careful optimization and tuning.
Overall, understanding large multimodal models is essential for realizing their full potential in various applications. By using LMMs’ capabilities to process and interpret multiple data types, AI systems can achieve greater sophistication and effectiveness in addressing real-world problems across different domains. As research and development in this area continue to progress, we can expect to see even more sophisticated and versatile LMMs in the future, unlocking new possibilities for AI-powered solutions.
Differentiating LMMs from Large Language Models (LLMs)
Here is a comparison of key aspects between Large Language Models (LLMs) and Large Multimodal Models (LMMs):
| Aspect | Large Language Models (LLMs) | Large Multimodal Models (LMMs) |
|---|---|---|
| Data modalities | Primarily textual data | Multiple types of data inputs, including text, images, audio, video, and sometimes other data types like sensory data |
| Applications and tasks | Centered around text-based tasks such as writing articles, translation, question-answering, summarization, and text-based content creation | Applied to tasks requiring integration across different types of data, such as analyzing news articles, images, and video clips for comprehensive understanding |
| Data collection and preparation | Focuses on gathering textual data from books, websites, and other written sources, emphasizing linguistic diversity and breadth | Requires not only textual data but also images, audio, video, and potentially other data types, involving complex data annotation and normalization |
| Model architecture design | Typically utilizes architectures suited for processing sequential data (text), such as transformers, with a focus on understanding and generating human language | Employs more complex architectures integrating different data inputs, combining neural network types like CNNs for images and RNNs or transformers for text, with mechanisms to fuse modalities effectively |
| Pre-training | Involves pre-training using large text corpora and techniques like masked language modeling, focusing on predicting missing words in sentences | More diverse pre-training involving not just text but also other modalities, such as correlating text with images or understanding sequences in videos |
| Fine-tuning | Fine-tuning is done using specialized text datasets tailored to specific tasks like question-answering or translation | Involves fine-tuning with specialized datasets for each modality and datasets helping the model learn cross-modal relationships, making task-specific adjustments more complex |
| Evaluation and iteration | Evaluated on metrics focused on language understanding and generation tasks, including fluency, coherence, and relevance | Evaluated on a wider range of metrics, including image recognition accuracy, audio processing quality, and the model’s ability to integrate information across modalities, reflecting versatility across multiple domains |
| Versatility and specialization | Specialize in text-centric tasks, limiting their applicability to tasks involving textual data. While they excel in tasks requiring language understanding and generation, they may not be as adept at handling other forms of data | Exhibit versatility in handling various data modalities, making them suitable for various applications across different domains. They can adapt to diverse use cases, from multimedia content analysis to interactive AI systems |
Elevate Your AI Projects with LMMs
Explore LeewayHertz’s expertise in AI development to take your
LMMs-powered applications to the next level.

Understanding the differences between LMMs and LLMs is essential for employing their respective strengths in different AI applications. While LMMs provide versatility and the ability to handle diverse data types, LLMs excel in tasks centered around textual data. By selecting the appropriate model based on the specific requirements of the task at hand, AI practitioners can utilize the full potential of these advanced AI technologies.
Tasks performed by Large Multimodal Models
Understanding the capabilities of large multimodal models (LMMs) entails exploring the diverse tasks they are engineered to handle. These tasks are broadly divided into two categories: generation and vision-language understanding (VLU), encompassing a wide array of applications leveraging both visual and textual inputs.
1. Generation
Generative tasks involve the creation of new content based on given inputs. In the domain of multimodal models, this encompasses:
- Image generation (text-to-image synthesis): In this task, the model interprets a textual description and generates a corresponding image. Examples include prominent tools like DALL-E, Stable Diffusion, and Midjourney.
- Text generation: Multimodal models enhance text generation tasks such as:
- Visual question answering: By amalgamating textual context with visual stimuli (images), the model can respond to queries about the image’s content. Imagine pointing a camera at an object and asking questions like “What’s the issue here?” or “How can I prepare this dish?”
- Image captioning: This entails producing captions that briefly describe the contents of an image. It proves particularly beneficial for image retrieval systems, facilitating user searches based on textual descriptions.
2. Vision-Language Understanding (VLU)
Vision-Language Understanding (VLU) encompasses two main task types: classification and text-based image retrieval (TBIR).
Classification: Classification models are designed to generate outputs that belong to a predefined list of classes. This approach is effective when the task involves predicting outcomes from a fixed set of outcomes. For instance, consider an Optical Character Recognition (OCR) system, which predicts whether a visual input corresponds to a known character (e.g., a digit or a letter).
Note: An OCR system operates at the character level. When combined with a system capable of understanding broader contexts, it enhances various applications, like comprehending entire documents, manuals, or contracts.

Document processing with GPT-4V. The model’s mistake is highlighted in yellow.
Image-to-text retrieval: This identifies textual descriptions (captions, reviews) that best align with a given image. It proves valuable for tasks like product image searches, enabling users to find reviews based on product images.
Text-based image retrieval (image search)
Image search emerges as a pivotal application of VLU, empowering users to locate images based on text queries. Two primary approaches include:
- Caption-based retrieval: This involves generating captions or metadata for images (either manually or automatically) and subsequently searching for images whose descriptions closely match the text query.
- Joint embedding space: This approach establishes a unified space where images and text are represented. A text query is converted into an embedding within this space, and the system then identifies images whose embeddings are most similar to the query embedding. This method, epitomized by OpenAI’s CLIP, is regarded as more flexible and potent.
Through these tasks, large multimodal models showcase their versatility in comprehending and synthesizing information across multiple modalities, ushering in innovative applications across diverse domains.
Data modalities of Large Multimodal Models
Large Multimodal Models (LMMs) are capable of comprehending and generating textual content, analyzing images, processing audio data, and handling video content, providing a versatile approach to understanding and interpreting diverse data types.
- Text
- Large Multimodal Models (LMMs) are equipped to handle textual data, ranging from books and articles to social media posts.
- These models can comprehend and generate textual content, enabling them to perform tasks such as language translation, summarization, and question-answering.
- Textual data provides valuable context and information for LMMs, allowing them to process and interpret human language effectively.
2. Images
- LMMs are designed to analyze and interpret visual data in the form of images.
- They can understand the content and context of photographs, illustrations, and other graphical representations.
- Image-related tasks performed by LMMs include image classification, object detection, and even generating images based on textual descriptions.
3. Audio
- With the capability to process audio data, LMMs can recognize speech, music, and other auditory inputs.
- They can transcribe speech, understand spoken commands, and even generate synthetic speech or music.
- Audio data adds another dimension to the input sources that LMMs can comprehend, making them more versatile in real-world applications.
4. Video
- LMMs are adept at handling video data, which combines visual and auditory elements.
- They can analyze video content, recognize actions or events within videos, and generate video clips.
- Video processing capabilities enable LMMs to understand moving images and their accompanying sounds, providing a richer understanding of visual information.
How do Large Multimodal Models work?
Large Multimodal Models (LMMs) work by integrating and processing information from multiple data modalities, such as text, images, audio, and video, to perform various tasks. Here’s a general overview of how they function:
- Data encoding: LMMs use specialized encoders for each modality to transform raw input data into vector representations known as embeddings. These embeddings capture the essential features of the data, making them suitable for further processing.
- Multimodal fusion: The embeddings from different modalities are then combined using fusion mechanisms. These mechanisms align and integrate the embeddings into a unified multimodal representation. Techniques like cross-attention layers or modality-specific adapters are commonly used for this purpose.
- Task-specific processing: Depending on the task at hand, LMMs may employ additional processing layers or components. For example, in generative tasks, a decoder might be used to generate output (e.g., text or images) based on the multimodal representation.
- Output generation: In generative tasks, LMMs generate output in a step-by-step manner. For example, in text generation, the model might predict each word sequentially, taking into account the multimodal context and the previously generated words.
- Training and optimization: LMMs are trained on large datasets using optimization algorithms. The training process involves adjusting the model’s parameters to minimize a loss function, which measures the difference between the model’s predictions and the ground truth data.
- Attention mechanisms: Attention mechanisms are often used in LMMs to enable the model to focus on relevant parts of the input data. This is particularly important in multimodal settings, where the model needs to selectively attend to information from different modalities.
Overall, LMMs leverage the strengths of multiple data modalities to perform complex tasks that require an understanding of diverse types of information. Their ability to process and integrate multimodal data makes them powerful tools for a wide range of applications, from natural language processing and computer vision to audio analysis and beyond.
It’s important to note that LMMs are a rapidly evolving field, and researchers are continuously exploring new architectures, alignment mechanisms, and training objectives to improve multimodal representation and generation capabilities. LMMs can be used for a wide range of tasks beyond text generation, including classification, detection, and more complex generative tasks involving multiple output modalities. The architecture and components of an LMM can vary depending on the specific task and modalities involved.
Use cases of LMMs across various industries
Here are some compelling use cases of Large Multimodal Models (LMMs) across diverse industries, showcasing their transformative impact on various applications:
1. Healthcare
Medical diagnosis and treatment assistance
- LMMs can analyze a patient’s medical history, symptoms, and diagnostic tests to assist healthcare providers in making accurate diagnoses and determining appropriate treatment plans.
- By processing textual descriptions of symptoms and analyzing medical images, LMMs can provide valuable insights and recommendations to healthcare professionals.

An example of how multimodality can be used in healthcare. Image from Multimodal biomedical AI (Acosta et al., Nature Medicine 2022)
Patient education and empowerment
- LMMs can be employed to generate personalized educational materials for patients, explaining complex medical concepts in easily understandable language.
- By incorporating text, images, and audio, LMMs can create interactive educational resources tailored to individual patients’ needs, empowering them to participate in their healthcare decisions actively.
Clinical documentation and administrative tasks
- LMMs streamline clerical and administrative tasks in managing digital health records.
- They can extract, organize, and process information from medical records, facilitating efficient data management and retrieval processes within healthcare institutions.
Scientific and nursing training
- LMMs are utilized in scientific and nursing training programs to simulate patient encounters.
- They create realistic scenarios for medical students and nurses to practice clinical skills, decision-making, and patient interactions in a controlled environment, enhancing their learning experience.
Research and drug development
- LMMs contribute to scientific research and drug development by analyzing vast amounts of biomedical data, literature, and clinical trial results.
- They assist researchers in identifying patterns, trends, and potential drug candidates, accelerating the process of discovery and innovation in healthcare.
2. Education
Diverse learning materials creation
- LMMs can transform the educational landscape by generating a wide range of engaging learning materials that incorporate text, images, audio, and even video.
- These materials cater to various learning styles and preferences, making learning more accessible and enjoyable for students.
Adaptive learning systems
- LMMs enable the development of adaptive learning systems that can understand and adapt to each student’s individual needs and learning pace.
Skill development through simulations
- Through the use of interactive simulations and real-world examples, LMMs support the development of practical skills and competencies.
- Students can engage in hands-on learning experiences that simulate real-life scenarios, helping them to apply theoretical knowledge in practical contexts and develop critical thinking and problem-solving skills.
3. Entertainment
Real-time movie translation
- LMMs can transform the entertainment industry by enabling real-time translation of movies into multiple languages, taking into account cultural nuances and context.
- This ensures that viewers worldwide can enjoy films in their native language without losing the essence of the original content.
Content generation and recommendations
- LMMs can generate and recommend personalized content recommendations for entertainment consumption based on a fusion of user preferences and behaviors.
- By analyzing data from various sources, including past viewing habits, social media interactions, and demographic information, LMMs can suggest personalized entertainment options tailored to individual tastes.
Art and music creation
- LMMs offer innovative possibilities in art and music creation by blending different modalities to produce unique and expressive outputs.
- For example, a LMM designed for art can combine visual and auditory elements to create immersive experiences, while a music-focused LMM can integrate instrumental and vocal elements for dynamic compositions.
4. Manufacturing
Defect detection
- Large Multimodal Models (LMMs) offer significant potential in defect detection within manufacturing processes.
- By integrating computer vision techniques with natural language processing capabilities, LMMs can analyze images of products to identify faults or defects efficiently.
- LMMs like GPT-4 demonstrate the ability to confidently detect various defects in the provided data.
- However, challenges may arise when dealing with uncommon products or variations in appearance, and LMMs may fail to make accurate predictions. Nonetheless, by refining prompts and incorporating reference images, LMMs can improve defect detection accuracy, highlighting their potential value in enhancing product quality and minimizing operational costs in manufacturing.
Safety inspection
In manufacturing environments, ensuring compliance with safety regulations is paramount to preventing workplace accidents and upholding employee well-being.
- LMMs can aid in safety inspections by analyzing visual data to monitor Personal Protective Equipment (PPE) compliance effectively. For instance, GPT-4’s performance in counting individuals wearing helmets, as shown in the figure below, demonstrates its ability to identify safety violations.
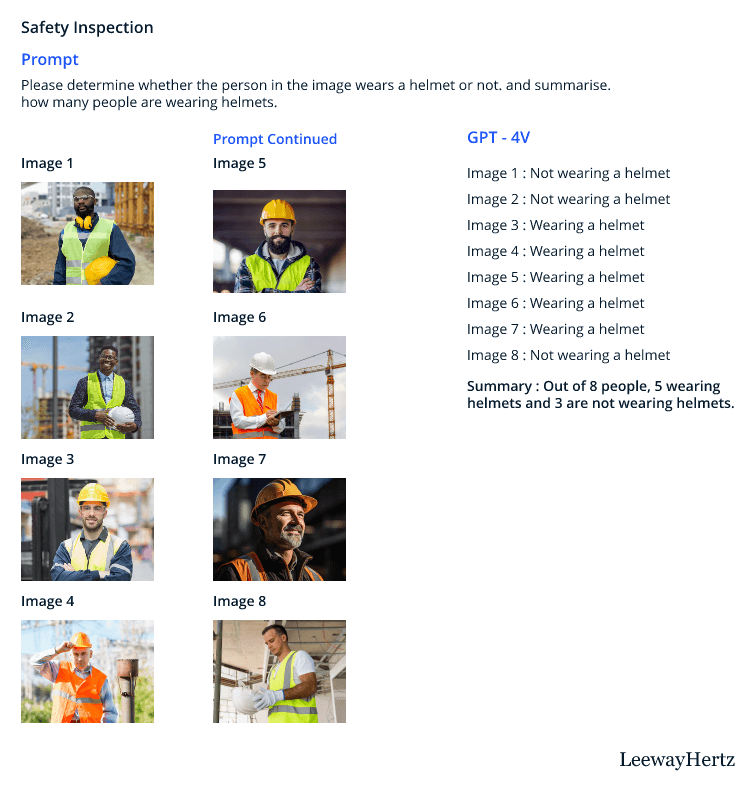
- Although challenges exist, such as detecting individuals not wearing helmets, leveraging external person detectors in combination with LMMs can improve accuracy. By accurately assessing PPE compliance and promptly addressing safety concerns, LMMs contribute to fostering a safer working environment in manufacturing facilities.
5. Retail
In the retail sector, Large Multimodal Models (LMMs) present diverse applications aimed at enhancing customer experiences and operational efficiency.
Grocery checkout:
- LMMs can transform the checkout process in retail stores by enabling automatic self-checkout systems.
- LMMs, by integrating computer vision with natural language understanding, can identify and ring up items in a shopping basket without user intervention, streamlining the checkout experience for customers. LMMs can identify grocery items accurately when provided with catalog images, showcasing the potential for automated self-checkout systems.
- While challenges exist, such as accurately identifying items without additional context, further research and development can refine LMMs’ capabilities, paving the way for more efficient and convenient checkout solutions in retail environments.
6. Auto-insurance
Large Multimodal Models (LMMs) offer valuable applications in the auto insurance industry, particularly in damage evaluation and car accident reporting.
Damage evaluation
- LMMs can assist auto insurance companies in accurately assessing the extent of damages sustained by vehicles involved in accidents. By analyzing images of damaged cars, LMMs like GPT-4 can identify and localize specific damages, providing detailed descriptions and even estimating repair costs.
- The proficiency demonstrated by LMMs in damage evaluation facilitates faster claims processing and more accurate assessment of insurance coverage, benefiting both insurers and policyholders.
Insurance reporting
- LMMs play a crucial role in automating insurance reporting processes for car accidents.
- By extracting relevant information from images, such as vehicle make, model, and license plate details, LMMs can generate comprehensive reports in JSON format.
- Although challenges exist, such as occlusions hindering information extraction, the demonstrated capabilities of LMMs underscore their potential to streamline insurance reporting procedures, enabling faster claim resolutions and improved customer service in the auto insurance industry.
7. Bio-medicine
In biomedicine, large multimodal models (LMMs) offer innovative solutions for various tasks, including pathology analysis, radiology report generation, and biomedical assistance.
- PathAsst: Redefining pathology through generative foundation AI assistant for pathology
- PMC-VQA: Visual instruction tuning for medical visual question answering
- LLaVA-Med: Training a large language-and-vision assistant for biomedicine
- The success of LMMs in general domains has inspired their application in bio-medicine, where they demonstrate remarkable promise in empowering biomedical practitioners. For instance, LLaVA-Med leverages a large-scale biomedical dataset to train a vision-language conversational assistant capable of answering open-ended research questions.
- By combining visual and textual information, LMMs facilitate tasks such as medical image understanding and radiology report generation, as evidenced by their proficiency in diagnosing conditions and providing accurate descriptions.
- LMMs’ ability to reference prior medical scans and diagnosis histories enhances their utility as AI assistants in bio-medicine, offering valuable support to medical professionals in diagnosis and treatment planning despite challenges like erroneous diagnoses and hallucinations.
LMM-powered agents

Large Multimodal Models (LMMs) have emerged as powerful tools for processing and understanding multimodal data, combining the capabilities of natural language processing (NLP) with other modalities such as images, audio, or video. In the subsequent section, we explore potential future research directions that may further amplify the capabilities of LMMs, focusing on the concept of LMM Agents.
Multimodal plugins
Multimodal plugins serve as crucial components in enhancing the functionality of LMMs. These plugins enable LMMs to access real-time information, perform computations, or utilize third-party services. By integrating plugins such as Bing Image Search and more, LMMs can access up-to-date information related to input images, significantly enhancing their understanding and reasoning abilities.
Multimodal chains
Multimodal chains represent an advanced paradigm where LMMs are integrated with a pool of plugins, allowing for sophisticated reasoning and interactions. By leveraging a combination of language and vision capabilities, multimodal chains enable LMMs to process and analyze multimodal information effectively. This integration opens up new possibilities for enhanced reasoning and interaction, empowering LMMs to tackle complex tasks with greater efficiency.
Self-reflection
Self-reflection techniques aim to improve LMM results by iteratively refining outputs based on feedback. This process enhances the alignment between model outputs and reference data, leading to improved accuracy and quality. Self-reflection enables LMMs to adapt and improve their performance over time, ensuring robustness and reliability in their outputs.
Self-consistency
Self-consistency strategies aggregate multiple sampled outputs to produce final answers, improving LMM reasoning performance. By employing techniques like the majority vote, self-consistency ensures consistency and reliability in LMM outputs, particularly in tasks such as counting problems. This approach enhances the overall robustness and accuracy of LMMs, making them more reliable in various applications.
Retrieval-augmented LMMs
Retrieval-augmented LMMs enhance text generation by retrieving and integrating relevant information into prompts. This approach is particularly effective in scenarios requiring specialized or task-relevant information, such as expert knowledge or customized data. By automatically retrieving relevant information, retrieval augmented LMMs can tailor outputs to specific user needs or domain requirements, improving the overall performance and usefulness of the models.
Notable Large Multimodal Models
Below is a summary of notable Large Multimodal Models (LMMs) along with their key features and use cases:
| Model name | Developed by | Features | Use cases |
| LLaVA | University of Wisconsin-Madison, Microsoft Research, Columbia University | Multimodal GPT4 variant, utilizing Meta’s Llama LLM, it incorporates CLIP visual encoder for robust visual comprehension | Healthcare-focused variant (LLaVA-Med) for answering inquiries related to biomedical images |
| ImageBind | Meta | Integrates six modalities: text, images/videos, audio, 3D measurements, temperature data, and motion data | Connects objects in photos with attributes like sound, 3D shapes, temperature, and motion; scene generation from text/sound |
| SeamlessM4T | Meta | Specializes in translation/transcription tasks (speech-to-speech, speech-to-text, text-to-speech, text-to-text); employs a non-autoregressive text-to-unit decoder to perform these translations | Fosters communication among multilingual communities; emphasizes the preservation of expression across languages and delivering translations with minimal latency |
| GPT4 | OpenAI | Smooth integration of text-only, vision-only, and audio-only models; adept at humor description, text summarization, etc. | Text generation from written/graphical inputs; versatile processing of various input data formats |
| Gemini | Google DeepMind | Inherently multimodal; manages text and diverse audio-visual inputs with ease | Effortlessly handles tasks across text and audio-visual domains; capable of generating outputs in text and image formats |
| Flamingo | DeepMind (OpenFlamingo), Google DeepMind (Flamingo) | Framework for training large multimodal models; based on Flamingo architecture with Perceiver resamplers | Tackling diverse vision-language tasks; aimed at matching GPT-4 in handling visual/text input |
| Unified-IO 2 | Allen Institute for AI | Autoregressive multimodal model understanding/generating images, text, audio, action; tokenizes inputs into a shared space | Performs tasks including captioning, free-form instructions, image editing, object detection, audio generation, and more |
These Large Multimodal Models (LMMs) showcase the forefront of AI, excelling in tasks like image understanding, text generation, translation, and multimodal communication. They highlight LMMs’ versatility in handling diverse data types and bridging the gap between vision and language domains.
Elevate Your AI Projects with LMMs
Explore LeewayHertz’s expertise in AI development to take your
LMMs-powered applications to the next level.
Benefits of LMMs for businesses

Utilizing the power of Large Multimodal Models (LMMs) can bring significant benefits to businesses across various industries. Here’s how LMMs can transform business operations:
- Informed decision-making:
Large Multimodal Models empower businesses to make more informed decisions by utilizing insights from multiple data modalities. Traditionally, businesses have relied on unimodal data analysis, such as text or numerical data, which may provide limited insights. However, LMMs can process and analyze text, images, audio, and video data simultaneously, providing a comprehensive understanding of complex scenarios. For instance, in retail, LMMs can analyze customer reviews (text), product images, and social media posts (images and text) to derive insights about consumer preferences, market trends, and competitor strategies. This holistic view enables businesses to make strategic decisions based on a deeper understanding of their operating environment.
2. Efficient automation:
LMMs are driving automation across industries by automating tasks that require understanding and generation of both text and visuals. This transformation is evident in industries like content creation, customer support, and marketing, leading to increased efficiency and reduced operational costs.
3. Optimized workflows:
Large Multimodal models simplify and automate complex workflows by processing and interpreting multiple data types simultaneously. This streamlining of processes saves time and resources, enabling businesses to operate more efficiently.
4. Expanding business horizons:
LMMs’ versatility opens up new business opportunities by enabling innovative applications and services that weren’t possible with traditional AI models. Businesses can leverage LMMs to develop cutting-edge solutions that cater to evolving customer needs and market trends.
5. Fostering contextual understanding:
Large Multimodal Models have a unique ability to understand context by analyzing both visual and textual data together. This contextual understanding enhances conversation-based systems, enabling more natural interactions with computers and smarter decision-making based on a comprehensive understanding of the situation.
6. Enhanced capabilities:
LMMs make AI systems much more capable by using data from different sources like text, images, audio, and video to understand the world and its context better. This broader understanding empowers AI systems to perform a wider range of tasks with greater accuracy, leading to smarter decisions and more efficient operations.
7. Enhancing performance and precision:
In natural language processing, multimodal models improve the understanding and generation of human language by incorporating visual information alongside textual data. This results in more meaningful responses and better user experiences across a wide range of applications, from virtual assistants to language translation services and content generation.
8. Personalization:
LMMs enable hyper-personalization by analyzing user behaviors, preferences, and interactions across different modalities. This allows businesses to offer highly personalized experiences to their customers, from tailored product recommendations to customized marketing content, ultimately driving engagement and loyalty. For instance, in e-commerce, LMMs can analyze both product descriptions and images to provide accurate recommendations that align with individual preferences.
Endnote
The development of Large Multimodal Models (LMMs) is progressing rapidly, driven by advancements in research and increasing computational capabilities. As these models continue to evolve, their potential to transform AI applications becomes increasingly evident.
As a natural progression, large multimodal models (LMMs)are expected to advance in generating interleaved image-text content that integrates textual descriptions and accompanying visuals, facilitating comprehensive multimodal content understanding and generation. Furthermore, expanding the scope of LMMs to incorporate diverse modalities will significantly enhance their capabilities, enabling more versatile and sophisticated interactions with multimedia information and real-world environments. This expansion will further enhance the versatility and richness of LMMs, enabling them to engage with and interpret a wide range of real-world information across multiple sensory domains.
In terms of learning, future LMMs could move beyond structured datasets to learn from diverse sources, including online content and real-world environments. This continuous self-evolution could empower LMMs to become intelligent assistants capable of understanding our multi-sensory world and generating creative outputs based on various inputs, ranging from visual stimuli to complex medical data.
Beyond their practical applications, LMMs have the potential to transform human-computer interaction, making communication with AI systems more natural and intuitive. This shift could foster deeper understanding and collaboration between humans and machines, paving the way for an era where AI seamlessly integrates into our daily lives.
However, alongside these advancements, it’s crucial to address ethical considerations surrounding bias, fairness, and transparency in AI development. As LMMs become increasingly sophisticated, responsible development and deployment practices are essential to ensure equitable and trustworthy AI systems. By proactively tackling these challenges, we can utilize the full potential of Large Multimodal Models to create a more intelligent, interconnected, and ethically sound future for everyone.
Discover the potential of Large Multimodal Models (LMMs) to transform your business. Connect with LeewayHertz’s AI experts today to build tailored LMM solutions to optimize your operations, streamline workflows and support informed decision-making.
Author’s Bio


Akash's ability to build enterprise-grade technology solutions has attracted over 30 Fortune 500 companies, including Siemens, 3M, P&G and Hershey’s.
Akash is an early adopter of new technology, a passionate technology enthusiast, and an investor in AI and IoT startups.
Related Services
LLM Development
Transform your AI capabilities with our custom LLM development services, tailored to your industry's unique needs.
Explore ServiceStart a conversation by filling the form
All information will be kept confidential.
Insights

AI in medicine: Exploring AI’s emerging role in patient care management
AI finds diverse applications in medicine, transforming various aspects of healthcare delivery and improving patient outcomes.

How attention mechanism’s selective focus fuels breakthroughs in AI
The attention mechanism significantly enhances the model’s capability to understand, process, and predict from sequence data, especially when dealing with long, complex sequences.

AI in Master Data Management (MDM): Pioneering next-generation data management strategies
In the intricate world of data management, the alliance between AI and MDM has surfaced as a vital driver for transforming data into actionable insights and informed decision-making.



